Hi, I'm Aniket Palaskar
Data Engineer • Distributed Systems • Backend Engineering
Building scalable data pipelines and distributed systems with a focus on event-driven architectures, real-time streaming, and cloud-native backend engineering. Experienced in designing reliable, production-grade systems that handle high-volume data workloads.
About Me
I help companies turn messy, high-volume data into reliable systems that teams can trust.
I'm a Data Engineer with 3+ years of experience designing and maintaining high-performance data systems. My expertise lies in building streaming and batch pipelines using tools like Python, RabbitMQ, and AWS.
I specialize in creating reliable, scalable systems that handle large volumes of data efficiently. With a strong foundation in distributed systems and data engineering principles, I focus on delivering solutions that are both performant and maintainable.
Data Engineering
Building robust data pipelines
Cloud Infrastructure
AWS, Docker, and DevOps
Performance Optimization
Scalable and efficient systems
Professional Experience
Software Developer | Provakil, Pune, India
Feb 2023 - Present- Engineered scalable Python scraping pipelines for 20+ national/state courts to ingest 5000+ case records daily
- Stored structured data, PDFs, and HTML efficiently in AWS S3, ensuring data accessibility and integrity
- Automated data quality checks, reducing manual validation efforts by 30% and improving data accuracy
- Designed and integrated data ingestion workflows with RabbitMQ, enabling multiple consumer services to process listings asynchronously; improved data freshness by 30% and increased system throughput by 25%
- Proactively debugged and resolved complex pipeline failures by analyzing logs in Elasticsearch and monitoring queues, reducing mean-time-to-resolution (MTTR) for data issues by 40%
- Developed automated notification systems using Pandas and Python, generating and delivering case summaries via email/WhatsApp, enhancing user engagement
- Collaborated with DevOps and backend teams on cross-service debugging, server configuration, and deployment processes
Production Engineering Highlights
- Reduced MTTR by 40% through proactive monitoring and log analysis
- Debugged asynchronous pipelines by analyzing queue backlogs and consumer behavior
- Collaborated across backend and DevOps teams during incident resolution
Technical Skills
Programming & Scripting
Python (Pandas, BeautifulSoup, Selenium, Django, Flask), SQL
Data Pipelines & Messaging
Apache Kafka, RabbitMQ, ETL/ELT, Cron, Distributed Systems
Cloud & DevOps
AWS, S3, EC2, CloudWatch, Docker, Git, CI/CD
Databases & Storage
MongoDB, TimescaleDB, PostgreSQL, Elasticsearch
Personal Projects
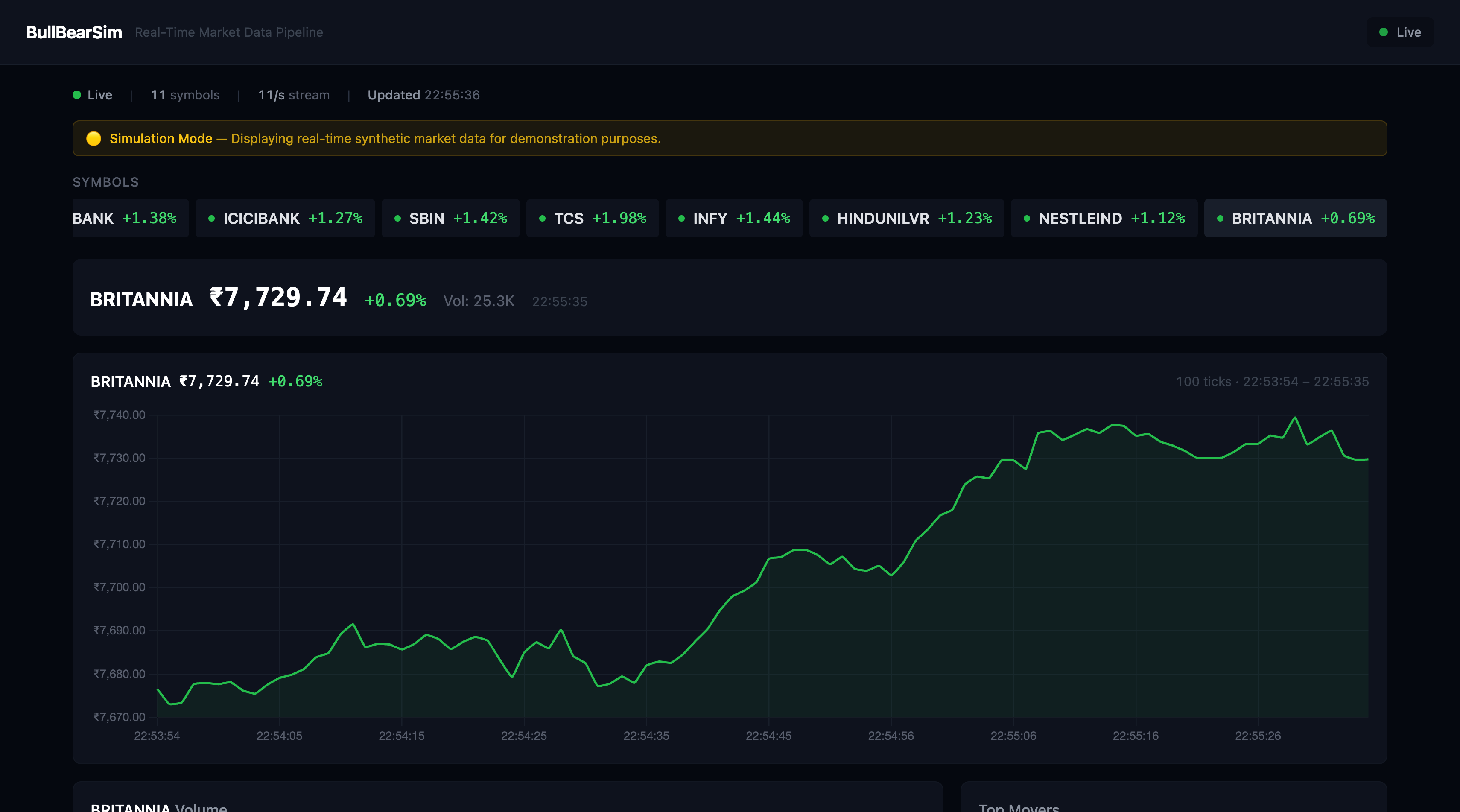
BullBearSim Featured
Production-ready real-time market data pipeline built with Python, Apache Kafka, TimescaleDB, FastAPI WebSockets, React, Docker, and AWS. Simulates live stock market data through a scalable streaming architecture with an interactive dashboard for real-time visualization and monitoring. Designed to demonstrate production-grade event-driven data engineering and cloud deployment.
Data Visualizer - Full-Stack Analytics Platform
Developed a full-stack analytics platform that enables users to upload datasets, process them with Pandas, and generate interactive visualizations. Built with Django and PostgreSQL, featuring responsive dashboards and data-driven insights.
Apache Airflow Fundamentals
Explored Apache Airflow fundamentals by building sample DAGs while following official documentation and tutorial resources. Practiced task dependencies, scheduling, retries, and failure handling using Python operators to understand batch workflow orchestration.
Apache Spark Data Processing
Explored Apache Spark concepts by running local PySpark jobs to process structured datasets. Practiced transformations, actions, and basic performance considerations to understand how distributed processing works at scale.
Education & Certifications
Education
B-Tech in Electronics and Telecommunication Engineering
Deogiri Institute of Engineering and Management Studies
2018 – 2022
Certifications
-
Python CertificationEdYoda Digital University2022
-
Data Science CertificationEdYoda Digital University2023
-
100 Days of Code: PythonUdemy2023
-
Python (Basic) & Problem Solving (Basic)HackerRank2023
Get In Touch
I'm open to new data engineering roles, collaborations, or freelance projects. Reach out if you'd like to discuss opportunities or projects.